

响应式开发之webFlux & Reactor
webFlux 初识
Lambda
Lambda 表达式,有时候也称为匿名函数或箭头函数,几乎在当前的各种主流的编程语言中都有它的身影。Java8 中引入 Lambda 表达式,使原本需要用匿名类实现接口来传递行为,现在通过 Lambda 可以更直观的表达。
- Lambda 表达式,也可称为闭包。闭包就是一个定义在函数内部的函数,闭包使得变量即使脱离了该函数的作用域范围也依然能被访问到。
- Lambda 表达式的本质只是一个”语法糖”,由编译器推断并帮你转换包装为常规的代码,因此你可以使用更少的代码来实现同样的功能。
- Lambda 表达式是一个匿名函数,即没有函数名的函数。有些函数如果只是临时一用,而且它的业务逻辑也很简单时,就没必要非给它取个名字不可。
- Lambda 允许把函数作为一个方法的参数(函数作为参数传递进方法中).
Lambda 表达式语法如下:形参列表=>函数体(函数体多于一条语句的可用大括号括起)。在 Java 里就是**() -> {}**:
(参数) -> 表达式
或
(参数) ->{ 代码语句 }
Lambda 表达式的重要特征:
- Lambda 表达式主要用来定义行内执行的方法类型接口,例如,一个简单方法接口。
- Lambda 表达式是通过函数式接口(必须有且仅有一个抽象方法声明)识别的
- 可选类型声明:不需要声明参数类型,编译器可以统一识别参数值。
- 可选的参数圆括号:一个参数无需定义圆括号,但多个参数需要定义圆括号。
- 可选的大括号:如果主体包含了一个语句,就不需要使用大括号。
- 可选的返回关键字:如果主体只有一个表达式返回值,则编译器会自动返回值,大括号需要指定表达式返回一个值。
Lambda 表达式中的变量作用域:
- 访问权限与匿名对象的方式非常类似。只能够访问局部对应的外部区域的局部 final 变量,以及成员变量和静态变量。
- 在 Lambda 表达式中能访问域外的局部非 final 变量、但不能修改 Lambda 域外的局部非 final 变量。因为在 Lambda 表达式中,Lambda 域外的局部非 final 变量会在编译的时候,会被隐式地当做 final 变量来处理。
- Lambda 表达式内部无法访问接口默认(default)方法
例子:使用 Java 8 之前的方法来实现对一个列表进行排序:
List<String> names = Arrays.asList("aaa", "cccc", "ddd", "bbb");
Collections.sort(names, new Comparator<String>() {
@Override
public int compare(String a, String b) {
return b.compareTo(a);
}
});
Java 8 Lambda 表达式:
Collections.sort(names, (String a, String b) -> {
return b.compareTo(a);
});
// 只有一条逻辑语句,可以省略大括号
Collections.sort(names, (String a, String b) -> b.compareTo(a));
// 可以省略入参类型
Collections.sort(names, (a, b) -> b.compareTo(a));
类型推断
通常 Lambda 表达式的参数并不需要显示声明类型。那么对于给定的 Lambda 表达式,程序如何知道对应的是哪个函数接口以及参数的类型呢?编译器通过 Lambda 表达式所在的上下文来进行目标类型推断,通过检查 Lambda 表达式的入参类型及返回类型,和对应的目标类型的方法签名是否一致,推导出合适的函数接口。比如:
Stream.of("我是字符串A", "我是字符串B").map(s -> s.length()).filter(l -> l == 3);
在上面的例子中,对于传入 map 方法的 Lamda 表达式,从 Stream 的类型上下文可以推导出入参是 String 类型,从函数的返回值可以推导出出参是整形类型,因此可推导出对应的函数接口类型为 Function;对于传入 filter 方法的 Lamda 表达式,从 pipeline 的上下文可得知入参是整形类型,因此可推导出函数接口 Predicate。
方法引用
Java 8 中还可以通过方法引用来表示 Lambda 表达式。方法引用是用来直接访问类或者实例的已经存在的方法或者构造方法。Java 8 允许你通过”::“关键字获取方法或者构造函数的引用。方法引用提供了一种引用而不执行方法的方式,它需要由兼容的函数式接口构成目标类型上下文。计算时,方法引用会创建函数式接口的一个实例。常用的方法引用有:
- 静态方法引用:ClassName::methodName
- 实例对象上的方法引用:instanceReference::methodName
- 类上的方法引用:ClassName::methodName
- 构造方法引用:Class::new
- 数组构造方法引用:TypeName[]::new
例子:
// 静态方法引用
Stream.of(someStringArray).allMatch(StringUtils::isNotEmpty);
// 实例对象上的方法引用
Stream.of(someStringArray).map(this::someTransform);
// 类上的方法引用
Stream.of(someStringArray).mapToInt(String::length);
// 构造方法引用
Stream.of(someStringArray).collect(Collectors.toCollection(LinkedList::new));
// 数组构造方法引用
Stream.of(someStringArray).toArray(String[]::new);
函数式接口
Java 8 中采用函数式接口作为Lambda 表达式的目标类型。函数式接口(Functional Interface)**是一个**有且仅有一个抽象方法声明的接口。任意只包含一个抽象方法的接口,我们都可以用来做成 Lambda 表达式。每个与之对应的 lambda 表达式必须要与抽象方法的声明相匹配。函数式接口与其他普通接口的区别:
- 函数式接口中只能有一个抽象方法(这里不包括与 Object 的方法重名的方法)
- 接口中唯一抽象方法的命名并不重要,因为函数式接口就是对某一行为进行抽象,主要目的就是支持 Lambda 表达式
- 自定义函数式接口时,应当在接口前加上**@FunctionalInterface**标注(虽然不加也不会有错误)。编译器会注意到这个标注,如果你的接口中定义了第二个抽象方法的话,编译器会抛出异常。
函数式编程
Java 来讲,从命令式编程到函数式编程的关键转变是从 Java8 多了一个 funtcion 包开始,在此基础上的 stream 更好的诠释了这一点,而之后 java 9 的 reactor,再到 spring5 的 webflux 都是在其基础上一步步演变的
java.util.function
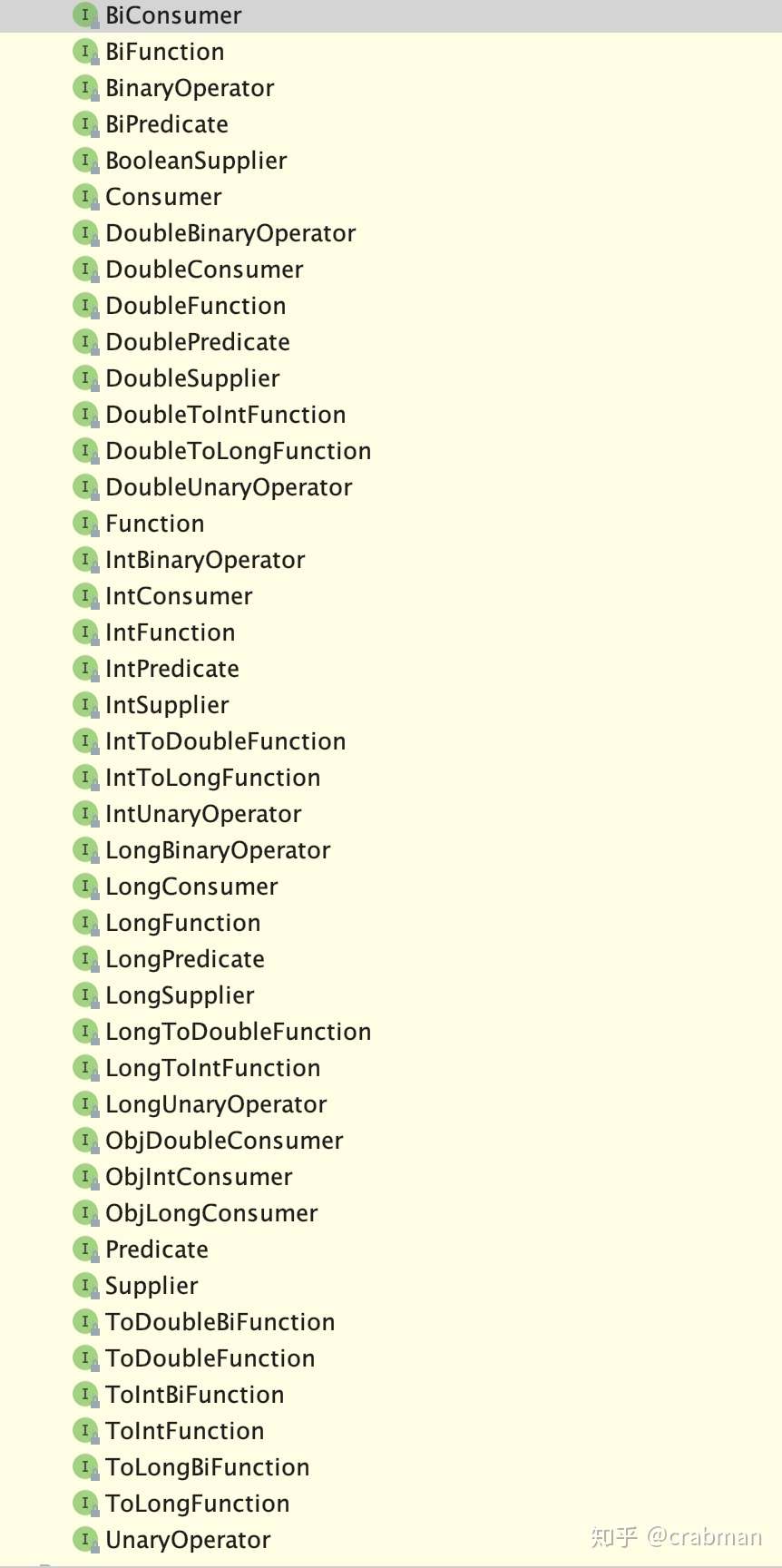
Function<T, R> stringIntegerFunction //输入T返回R的函数
Predicate<T> predicate //输入T,返回boolean值,断言(谓词)函数
Consumer<T> consumer; //消费者函数,消费一个数据
Supplier<T> supplier; // 生产者函数,提供数据
Function
/**
* 将范型T对象应用到输入的参数上,然后返回计算结果
*
* @param t the function argument
* @return the function result
*/
R apply(T t);
/**
* 返回一个先执行before函数对象apply方法再执行当前函数对象apply方法的函数对象
*
* @param <V> 前置函数的的输入类型,以及函数的输入类型 由函数
*
*/
default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {
Objects.requireNonNull(before);
return (V v) -> apply(before.apply(v));
}
/**
* 返回一个先执行当前函数对象apply方法再执行after函数对象apply方法的函数对象。
* <br>
* compose 和 andThen 的不同之处是函数执行的顺序不同。compose 函数先执行参数,
* 然后执行调用者,而 andThen 先执行调用者,然后再执行参数。
* </br>
*/
default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {
Objects.requireNonNull(after);
return (T t) -> after.apply(apply(t));
}
/**
* 返回输入结果
*/
static <T> Function<T, T> identity() {
return t -> t;
}
标注为 FunctionalInterface 的接口被称为函数式接口,该接口只能有一个自定义方法,但是可以包括从 object 类继承而来的方法。如果一个接口只有一个方法,则编译器会认为这就是一个函数式接口。
是否是一个函数式接口,需要注意的有以下几点:
- 该注解只能标记在”有且仅有一个抽象方法”的接口上。
- JDK8 接口中的静态方法和默认方法,都不算是抽象方法。
- 接口默认继承 java.lang.Object,所以如果接口显示声明覆盖了 Object 中方法,那么也不算抽象方法。
- 该注解不是必须的,如果一个接口符合”函数式接口”定义,那么加不加该注解都没有影响。加上该注解能够更好地让编译器进行检查。如果编写的不是函数式接口,但是加上了@FunctionInterface,那么编译器会报错。
- 在一个接口中定义两个自定义的方法,就会产生 Invalid ‘@FunctionalInterface’ annotation; FunctionalInterfaceTest is not a functional interface 错误.
响应式
响应式流(Reactive Streams)通过定义一组实体,接口和互操作方法,给出了实现异步非阻塞背压的标准。第三方遵循这个标准来实现具体的解决方案,常见的有 Reactor,RxJava,Akka Streams,Ratpack 等。
响应式编程(reactive programming)是一种基于数据流(data stream)和变化传递(propagation of change)的声明式(declarative)的编程范式
一个通用的流处理架构一般会是这样的(生产者产生数据,对数据进行中间处理,消费者拿到数据消费)

- 数据来源,一般称为生产者(Producer)
- 数据的目的地,一般称为消费者(Consumer)
- 在处理时,对数据执行某些操作一个或多个处理阶段。(Processor)
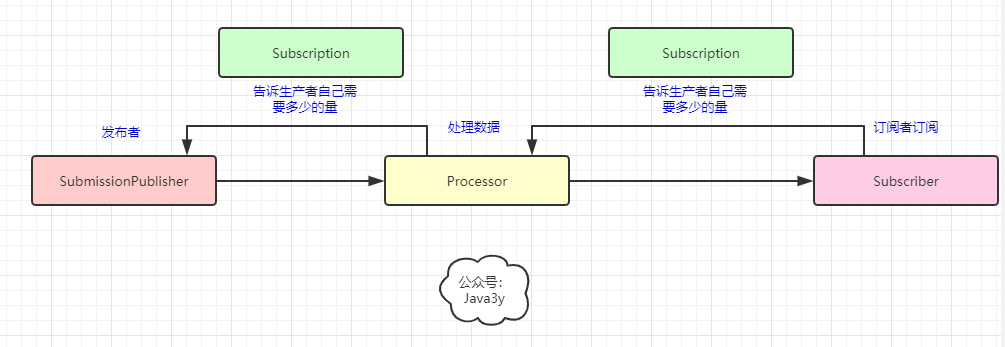
规范定义了 4 个接口
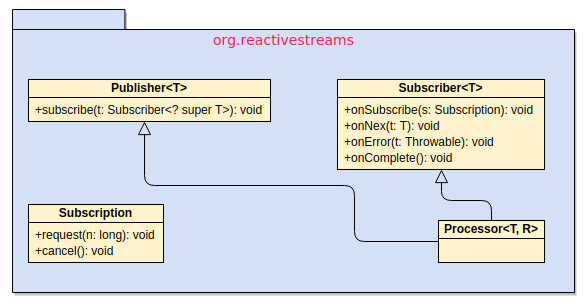
在响应式流上提到了 back pressure(背压)这么一个概念。在响应式流实现异步非阻塞是基于生产者和消费者模式的,而生产者消费者很容易出现的一个问题就是:生产者生产数据多了,就把消费者给压垮了
通俗就是: 消费者能告诉生产者自己需要多少量的数据。这里就是Subscription接口所做的事
特质
原文:https://www.reactivemanifesto.org/zh-CN
即时响应性: :只要有可能, 系统就会及时地做出响应。 即时响应是可用性和实用性的基石, 而更加重要的是,即时响应意味着可以快速地检测到问题并且有效地对其进行处理。 即时响应的系统专注于提供快速而一致的响应时间, 确立可靠的反馈上限, 以提供一致的服务质量。 这种一致的行为转而将简化错误处理、 建立最终用户的信任并促使用户与系统作进一步的互动。
- *回弹性:**系统在出现失败时依然保持即时响应性。 这不仅适用于高可用的、 任务关键型系统——任何不具备回弹性的系统都将会在发生失败之后丢失即时响应性。 回弹性是通过复制、 遏制、 隔离以及委托来实现的。 失败的扩散被遏制在了每个组件内部, 与其他组件相互隔离, 从而确保系统某部分的失败不会危及整个系统,并能独立恢复。 每个组件的恢复都被委托给了另一个(外部的)组件, 此外,在必要时可以通过复制来保证高可用性。 (因此)组件的客户端不再承担组件失败的处理。
弹性: 系统在不断变化的工作负载之下依然保持即时响应性。 反应式系统可以对输入(负载)的速率变化做出反应,比如通过增加或者减少被分配用于服务这些输入(负载)的资源。 这意味着设计上并没有争用点和中央瓶颈, 得以进行组件的分片或者复制, 并在它们之间分布输入(负载)。 通过提供相关的实时性能指标, 反应式系统能支持预测式以及反应式的伸缩算法。 这些系统可以在常规的硬件以及软件平台上实现成本高效的弹性。
- *消息驱动:**反应式系统依赖异步的消息传递,从而确保了松耦合、隔离、位置透明的组件之间有着明确边界。 这一边界还提供了将失败作为消息委托出去的手段。 使用显式的消息传递,可以通过在系统中塑造并监视消息流队列, 并在必要时应用回压, 从而实现负载管理、 弹性以及流量控制。 使用位置透明的消息传递作为通信的手段, 使得跨集群或者在单个主机中使用相同的结构成分和语义来管理失败成为了可能。 非阻塞的通信使得接收者可以只在活动时才消耗资源, 从而减少系统开销。

大型系统由多个较小型的系统所构成, 因此整体效用取决于它们的构成部分的反应式属性。 这意味着, 反应式系统应用着一些设计原则,使这些属性能在所有级别的规模上生效,而且可组合。
Reactive
官网 https://projectreactor.io/docs/core/release/reference/index.html#which.windowprojectreactor.io
在 reactor 中有两个最基本的概念,发布者和订阅者,可以理解为生产者和消费者的概念。在 Reactor 中发布者有两个,一个是Flux,一个是Mono。 Flux 代表的是 0-N 个元素的响应式序列,而 Mono 代表的是 0-1 个的元素的结果。
在 Reactive 中
- Publisher(发布者)相当于生产者(Producer)
- Subscriber(订阅者)相当于消费者(Consumer)
- Processor 就是在发布者与订阅者之间处理数据用的
// 发布者(生产者)public interface Publisher<T> { // 可以被订阅多次,每次生成新的Subscriber,每个消费者只能订阅一次Publisher,执行过程出错会直接报error public void subscribe(Subscriber<? super T> s);}// 订阅者(消费者)public interface Subscriber<T> { //该方法在订阅Publisher之后执行,在订阅之前不会有数据流的消费 public void onSubscribe(Subscription s); /** * 消费下一个消息,在执行request方法之后通知Publisher, *可被调用多次,有request(x),参数x决定执行几次 */ public void onNext(T t); //执行出错调用方法 public void onError(Throwable t); //执行完成之后调用方法 public void onComplete();}// 用于发布者与订阅者之间的通信(实现背压:订阅者能够告诉生产者需要多少数据)public interface Subscription { //消费请求 public void request(long n); //取消请求 public void cancel();}// 用于处理发布者 发布消息后,对消息进行处理,再交由消费者消费public interface Processor<T,R> extends Subscriber<T>, Publisher<R> {}
Mono (返回 0 或 1 个元素)
Mono 是响应流 Publisher 具有基础 rx 操作符。可以成功发布元素或者错误。如图所示:

常用方法
Mono.create(); //:使用 MonoSink 来创建 MonoMono.justOrEmpty(); //:从一个 Optional 对象或 null 对象中创建 Mono。 只有 Optional 对象中包含值或对象不为 null 时,Mono 序列才产生对应的元素。Mono.error(); //:创建一个只包含错误消息的 MonoMono.never(); //:创建一个不包含任何消息通知的 MonoMono.delay(); //:在指定的延迟时间之后,创建一个 Mono,产生数字 0 作为唯一值Mono.just(); //创建一个不为null的数据流 声明的参数就是数据流的元素 创建出来的 Mono序列在发布这些元素之后会自动结束/**注释同下*/Mono.fromCallable(); // 从回调函数生产数据 CallableMono.fromCompletionStage(); //异步任务中 CompletionStage Mono.fromFuture(); //异步任务中 CompletableFutureMono.fromRunnable(); // 异步任务 RunnableMono.fromSupplier()://Supplier 提供着
*Flux **(返回 0-n 个元素)
Flux 是响应流 Publisher 具有基础 rx 操作符。可以成功发布 0 到 N 个元素或者错误。Flux 其实是 Mono 的一个补充。如图所示:

所以要注意:如果知道 Publisher 是 0 或 1 个,则用 Mono。
Flux 最值得一提的是 fromIterable 方法。 fromIterable(Iterable<? extends T> it) 可以发布 Iterable 类型的元素。

当调用 just 方法,查看源码可以得知,返回的是一个 Flux
/** * Create a {@link Flux} that emits the items contained in the provided array. * <p> * <img class="marble" src="doc-files/marbles/fromArray.svg" alt=""> * * @param array the array to read data from * @param <T> The type of values in the source array and resulting Flux * * @return a new {@link Flux} */ public static <T> Flux<T> fromArray(T[] array) { if (array.length == 0) { return empty(); } if (array.length == 1) { return just(array[0]); } return onAssembly(new FluxArray<>(array)); }final class FluxArray<T> extends Flux<T> implements Fuseable, SourceProducer<T> { final T[] array; //存储数据 @SafeVarargs public FluxArray(T... array) { this.array = Objects.requireNonNull(array, "array"); } @SuppressWarnings("unchecked") //订阅方法 public static <T> void subscribe(CoreSubscriber<? super T> s, T[] array) { if (array.length == 0) { Operators.complete(s); return; } if (s instanceof ConditionalSubscriber) { // 此处是个啥? s.onSubscribe(new ArrayConditionalSubscription<>((ConditionalSubscriber<? super T>) s, array)); } else { s.onSubscribe(new ArraySubscription<>(s, array)); } } // 正常消费者 static final class ArraySubscription<T> implements InnerProducer<T>, SynchronousSubscription<T> { final CoreSubscriber<? super T> actual; final T[] array; //存储数据 int index; volatile boolean cancelled; //记录是否取消 volatile long requested; //记录请求多少次 @SuppressWarnings("rawtypes") static final AtomicLongFieldUpdater<ArraySubscription> REQUESTED = AtomicLongFieldUpdater.newUpdater(ArraySubscription.class, "requested"); ArraySubscription(CoreSubscriber<? super T> actual, T[] array) { this.actual = actual; this.array = array; } @Override public void request(long n) { if (Operators.validate(n)) { if (Operators.addCap(REQUESTED, this, n) == 0) { if (n == Long.MAX_VALUE) { fastPath(); } else { slowPath(n); } } } }
流程
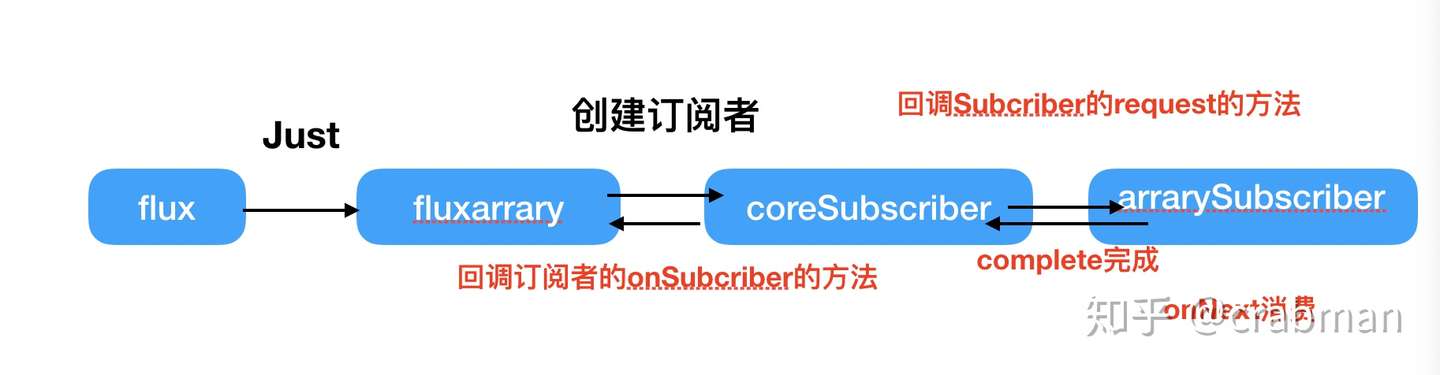
内置的 Processor
Processor既是一种特别的发布者(Publisher)又是一种订阅者(Subscriber)。 所以你能够订阅一个Processor,也可以调用它们提供的方法来手动插入数据到序列,或终止序列。
一直在聊响应式流的四个接口中的三个:Publisher、Subscriber、Subscription,唯独 Processor 迟迟没有提及。原因在于想用好它们不太容易,多数情况下,我们应该进行避免使用 Processor,通常来说仅用于一些特殊场景。
Reactor Core 内置多种 Processor。这些 processor 具有不同的语法,大概分为三类。
- 直接的(direct)(DirectProcessor 和 UnicastProcessor):这些 processors 只能通过直接 调用 Sink 的方法来推送数据。
- 同步的(synchronous)(EmitterProcessor 和 ReplayProcessor):这些 processors 既可以直接调用 Sink 方法来推送数据,也可以通过订阅到一个上游的发布者来同步地产生数据。
- 异步的(asynchronous)(WorkQueueProcessor 和 TopicProcessor):这些 processors 可以将从多个上游发布者得到的数据推送下去。由于使用了 RingBuffer 的数据结构来缓存多个来自上游的数据,因此更加有健壮性。
异步的 processor 在实例化的时候最复杂,因为有许多不同的选项。因此它们暴露出一个 Builder 接口。 而简单的 processors 有静态的工厂方法。
DirectProcessor
`DirectProcessor` 可以将信号分发给零到多个订阅者(Subscriber)。它是最容易实例化的,使用静态方法 create() 即可。另一方面,它的不足是无法处理背压。所以,当DirectProcessor推送的是 N 个元素,而至少有一个订阅者的请求个数少于 N 的时候,就会发出一个IllegalStateException。
一旦 Processor 结束(通常通过调用它的 Sink 的 error(Throwable) 或 complete() 方法), 虽然它允许更多的订阅者订阅它,但是会立即向它们重新发送终止信号。
UnicastProcessor
`UnicastProcessor`可以使用一个内置的缓存来处理背压。代价就是它最多只能有一个订阅者(上一节的例子通过publish转换成了ConnectableFlux,所以可以接入两个订阅者)。
UnicastProcessor 有多种选项,因此提供多种不同的 create 静态方法。例如,它默认是 无限的(unbounded) :如果你在在订阅者还没有请求数据的情况下让它推送数据,它会缓存所有数据。
可以通过提供一个自定义的 Queue 的具体实现传递给 create 工厂方法来改变默认行为。如果给出的队列是有限的(bounded), 并且缓存已满,而且未收到下游的请求,processor 会拒绝推送数据。
在“有限的”队列中,还可以在构造 processor 的时候提供一个回调方法,这个回调方法可以在每一个 被拒绝推送的元素上调用,从而让开发者有机会清理这些元素。
EmitterProcessor
`EmitterProcessor`能够向多个订阅者发送数据,并且可以对每一个订阅者进行背压处理。它本身也可以订阅一个发布者并同步获得数据。
最初如果没有订阅者,它仍然允许推送一些数据到缓存,缓存大小由bufferSize定义。 之后如果仍然没有订阅者订阅它并消费数据,对onNext的调用会阻塞,直到有订阅者接入 (这时只能并发地订阅了)。
因此第一个订阅者会收到最多 bufferSize 个元素。然而之后,后续接入的订阅者只能获取到它们开始订阅之后推送的数据。这个内部的缓存会继续用于背压的目的。
默认情况下,如果所有的订阅者都取消了订阅,它会清空内部缓存,并且不再接受更多的订阅者。这一点可以通过 create 静态工厂方法的 autoCancel 参数来配置。
ReplayProcessor
ReplayProcessor会缓存直接通过自身的 Sink 推送的元素,以及来自上游发布者的元素, 并且后来的订阅者也会收到重发(replay)的这些元素。
可以通过多种配置方式创建它:
- 缓存一个元素(cacheLast)。
- 缓存一定个数的历史元素(create(int)),所有的历史元素(create())。
- 缓存基于时间窗期间内的元素(createTimeout(Duration))。
- 缓存基于历史个数和时间窗的元素(createSizeOrTimeout(int, Duration))。
TopicProcessor
TopicProcessor是一个异步的 processor,它能够重发来自多个上游发布者的元素, 这需要在创建它的时候配置shared(build() 的 share(boolean) 配置)。
如果你企图在并发环境下通过并发的上游发布者调用 TopicProcessor 的 onNext、 onComplete,或 onError 方法,就必须配置 shared。否则,并发调用就是非法的,从而 processor 是完全兼容响应式流规范的。
TopicProcessor 能够对多个订阅者发送数据。它通过对每一个订阅者关联一个线程来实现这一点, 这个线程会一直执行直到 processor 发出 onError 或 onComplete 信号,或关联的订阅者被取消。 最多可以接受的订阅者个数由构造者方法 executor 指定,通过提供一个有限线程数的 ExecutorService 来限制这一个数。
这个 processor 基于一个 RingBuffer 数据结构来存储已发送的数据。每一个订阅者线程 自行管理其相关的数据在 RingBuffer 中的索引。
这个 processor 也有一个 autoCancel 构造器方法:如果设置为 true(默认的),那么当 所有的订阅者取消之后,上游发布者也就被取消了。
WorkQueueProcessor
WorkQueueProcessor也是一个异步的 processor,也能够重发来自多个上游发布者的元素, 同样在创建时需要配置shared(它多数构造器配置与TopicProcessor相同)。
它放松了对响应式流规范的兼容,但是好处就在于相对于 TopicProcessor 来说需要更少的资源。 它仍然基于 RingBuffer,但是不再要求每一个订阅者都关联一个线程,因此相对于 TopicProcessor 来说更具扩展性。
代价在于分发模式有些区别:来自订阅者的请求会汇总在一起,并且这个 processor 每次只对一个 订阅者发送数据,因此需要循环(round-robin)对订阅者发送数据,而不是一次全部发出的模式(无法保证完全公平的循环分发)。
WorkQueueProcessor 多数构造器方法与 TopicProcessor 相同,比如 autoCancel、share, 以及 waitStrategy。下游订阅者的最大数目同样由构造器 executor 配置的 ExecutorService 决定。
- *注意:**最好不要有太多订阅者订阅 WorkQueueProcessor,因为这会锁住 processor。如果你需要限制订阅者数量,最好使用一个 ThreadPoolExecutor 或 ForkJoinPool。这个 processor 能够检测到(线程池)容量并在订阅者过多时抛出异常。
完成信号
对于 Flux 和 Mono 来说,just 是数据完成的信号,那如果不是通过 just 声明的数据流,没有这种数据准备完成的信号,那么这个流就是一个无限流。除了我们手动声明数据准备的完成,错误信号也标志这整个流的完成。
Flux.error(new RuntimeException());
还有一种情况就是当 Flux 和 Mono 没有发出任何一个元素,而是直接发出了完成信号,那么这个流就是一个空的流,像这样。
Flux.error(new RuntimeException()); Flux.just(); Flux.empty();
还有很重要的一点就是 Flux.just(1,2,4) 只是定义了一个数据流而已,在subscribe() 之前的操作什么也不会发生,类似 Stream的惰性求值,在中止操作之前的操作都不会触发。
例如打印声明的数据流需要这样做
Flux.just(1, 2, 3).subscribe(System.out::println);
另外 subscribe 时,还可以指定错误的回调处理,以及数据处理完的完成回调
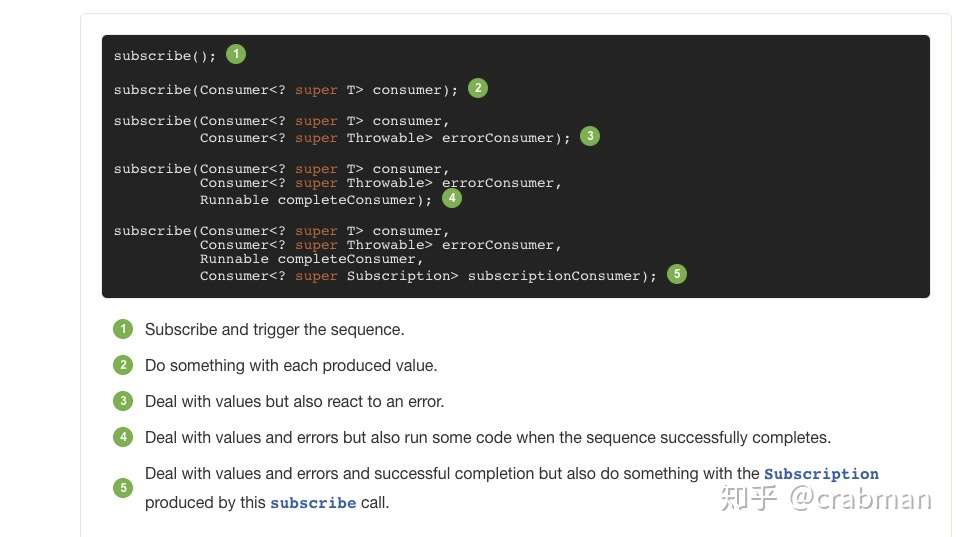
所以可以这样写
Flux.error(new Exception("error")).subscribe( System.out::println, System.err::println, () -> System.out.println("Completed!"));
流程:
流量控制(背压)
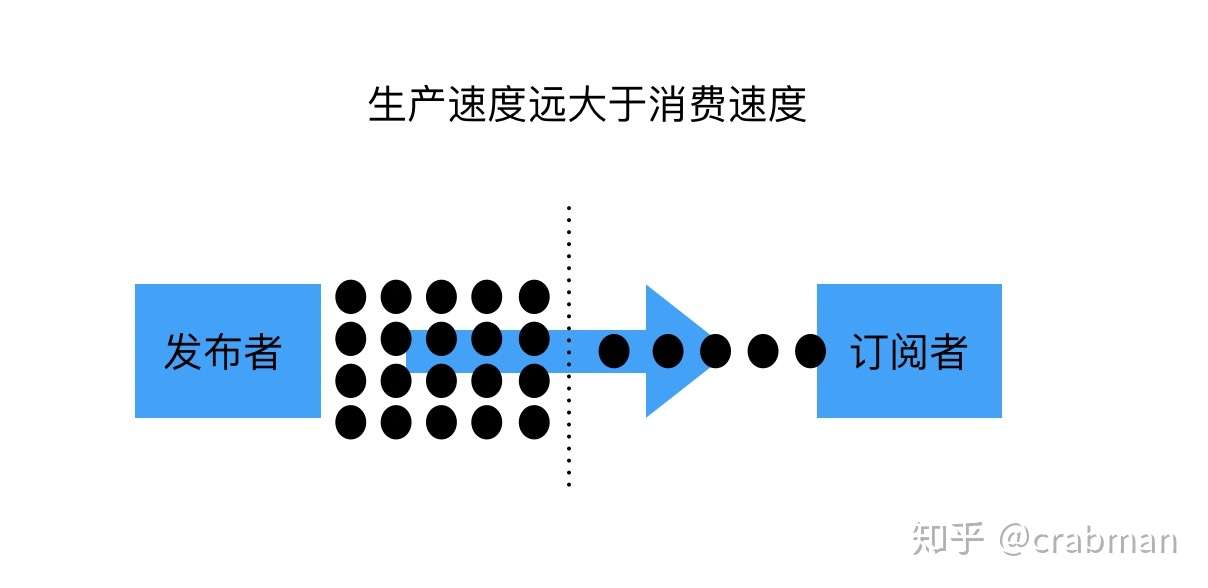
上面提到了一个问题,当生产者生产的速度远远大于消费者消费的的速度的时候,会引发任务大量堆积的情况,最终压垮整个管道。
那么响应式是怎么解决这个问题的,通过背压(back pressure)的机制,如下图
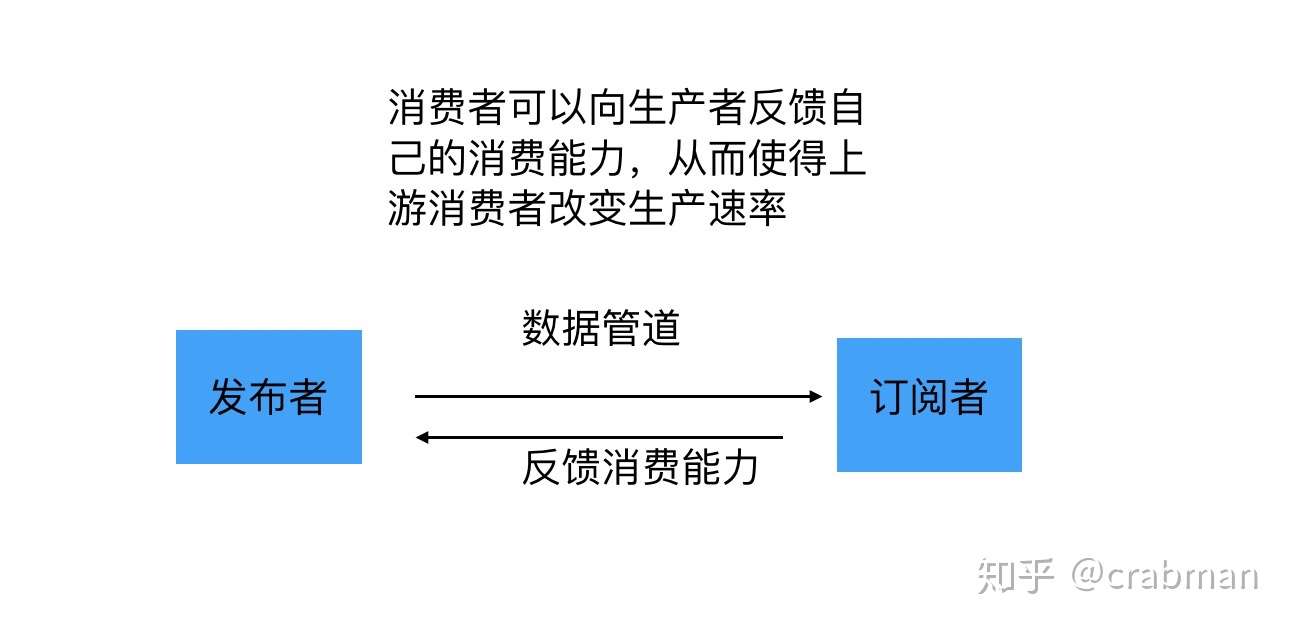
这种下游可以向上游反馈自己消费能力的机制就叫做背压,具体背压的原理和运行机制会在后面的实战中带入,因为很多刚接触这种概念的同学只听理论的话会一时很难理解。
通过 Reactor 提供的 BaseSubscriber 来进行自定义我们自己流量控制的 subscriber
Flux.just(1,2) .doOnRequest(s->System.out.println("no. "+s)) .subscribe(new BaseSubscriber<Integer>() { @Override protected void hookOnSubscribe(Subscription subscription) { System.out.println("订阅开始了,我要请求几个元素"); request(1); } @Override protected void hookOnNext(Integer value) { System.out.println("收到一个元素,下一次请求几个元素"); request(1); } });
Reactor 中的多线程
在我们 java 的传统的编程中,对于线程之间的调度有封装好的线程池工具类供我们使用,或者我们可以通过线程池的构造函数定义自己的线程池,这一切都让多线程的调度都变得很容易,那么在 reactor 中怎么处理线程的调度
4.1 Schedulers
在 reactor 中处理线程调度的不叫 thread pool,而是 Schedulers(调度器),通过调度器就可以创建出供我们直接使用的多线程环境。
4.1.1 Schedulers.immediate()
在当前线程中使用
4.1.2 Schedulers.single()
创建一个可重用的单线程环境,该方法的所有调用者都会重复使用同一个线程。
4.1.3 Schedulers.elastic()
创建一个弹性线程池,会重用空闲线程,当线程池空闲时间过长就会自动废弃掉。通常使用的场景是给一个阻塞的任务分配自己的线程,从而不会影响到其他任务的执行。
4.1.4 Schedulers.parallel()
创建一个固定大小的线程池,线程池大小和 cpu 个数相等。
来看一个具体使用的实例,通过 Schedulers.elastic() 将一个同步阻塞的方法改写成异步的。
private Integer syncMethod(){ try { TimeUnit.SECONDS.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } return 123456; } @Test public void switchSyncToAsyncTest(){ CountDownLatch countDownLatch = new CountDownLatch(1); Mono.fromCallable(()->syncMethod()) .subscribeOn(Schedulers.elastic()) .subscribe(System.out::println,null,countDownLatch::countDown); try { countDownLatch.await(); } catch (InterruptedException e) { e.printStackTrace(); } }
简单分析上述代码,通过 fromCallable 声明 一个 callable 的 mono,然后通过 subscribeOn 切换环境,调度任务到单独的弹性线程池工作。
错误处理
在传统的编程中,我们处理单个接口错误的方式,可能是 try-catch-finally 的方式,也可能是 try-winth-resource 的语法糖,这些在 reactor 中变得不太一样。下面来说一说 reactor 中的几种错误处理方式。
5.1 onErrorReturn
onErrorReturn 在发生错误的时候,会提供一个缺省值,类似于安全取值的问题,但是这个在响应式流里面会更加实用。
Flux.just(1,2,0) .map(v->2/v) .onErrorReturn(0) .map(v->v*2) .subscribe(System.out::println,System.err::println);
这样就可以在处理一些未知元素的时候,又不想让未知因素中止程序的继续运行,就可以采取这种方式。
5.2 onErrorResume
在发生错误的时候,提供一个新的流或者值返回,这样说可能不太清楚,看代码。
Flux.just(1,2,0) //调用redis服务获取数据 .flatMap(id->redisService.getUserByid(id)) //当发生异常的时候,从DB用户服务获取数据 .onErrorResume(v->userService.getUserByCache(id));
类似于错误的一个 callback;
5.3 onErrorMap
上面的都是我们去提供缺省的方法或值处理错误,但是有的时候,我们需要抛出错误,但是需要将错误包装一下,可读性好一点,也就是抛出自定义异常。
Flux.just(1,2,0) .flatMap(id->getUserByid(id)) .onErrorMap(v->new CustomizeExcetion("服务器开小差了",v));
5.4 doOnError 记录错误日志
在发生错误的时候我们需要记录日志,在 reactor 里面专门独立出 api 记录错误日志
Flux.just(1,2,0) .flatMap(id->getUserByid(id)) .doOnError(e-> Log.error("this occur something error")) .onErrorMap(v->new CustomizeExcetion("服务器开小差了",v));
doOnError 对于流里面的元素只读,也就是他不会对流里面的任务元素操作,记录日志后,会讲错误信号继续抛到后面,让后面去处理。
5.5 finally 确保做一些事情
有的时候我们想要像传统的同步代码那样使用 finally 去做一些事情,比如关闭 http 连接,清理资源,那么在 reactor 中怎么去做 finally
Flux.just(1,2,0) .flatMap(id->getUserByid(id)) .doOnError(e-> Log.error("this occur something error")) .onErrorMap(v->new CustomizeExcetion("服务器开小差了",v)) .doFinally(System.out.println("我会确保做一些事情")) ;
或者当我们打开一个连接需要关闭资源的时候,还可以这样写
Flux.using( () -> createHttpClient(), client -> Flux.just(client.sendRequest()), createHttpClient::close );
使用 using 函数的三个参数,获取 client,发送请求,关闭资源。
5.6 retry 重试机制
当遇到一些不可控因素导致的程序失败,但是代码逻辑确实是正确的,这个时候需要重试机制。
Flux.just(1,2,0) .map(v->2/v) .retry(1) .subscribe(System.out::println,System.err::println);
但是需要注意的是重试不是从错误的地方开始重试,相当于对 publisher 的重订阅,也就是从零开始重新执行一遍,所以无法达到类似于断点续传的功能,所以使用场景还是有限制。
如何调试 reactor
在我们传统阻塞代码里面,调试(Debug)的时候是一件非常简单的事情,通过打断点,得到相关的 stack 的信息,就可以很清楚的知道错误信息(不过在多线程的环境下去打断点,需要切换线程环境,也有点麻烦)。
但是在 reactor 环境下去调试代码并不是一件简单的事情,最常见的就是 一个 Flux 流,怎么去得到每个元素信息,怎么去知道在管道里面下一个元素是什么,每个元素是否像期望的那样做了操作。所以这也是从传统编程切换到响应式编程的难点,开发人员需要花时间去学习这个操作,但是感觉难受总是好的,因为做什么都太容易的话,自己会长期止步于此,像早期的 EJB 到 j2ee,ssh -> ssm -> spring boot -> spring cloud ,从微服务->service mesh -> serve less ,到现在一些一线大厂盛行的中台。也许这一次就是改变自己的时候。
言归正传,关于比较复杂的调试后期再说,我们先从最基本的单元测试开始。官方推荐的工具是 StepVerifier
@Test public void reactorTest(){ StepVerifier.create(Flux.just(1,2)) //1 .expectNext(1,2) //2 .expectComplete() //3 .verify(); //4 }
- 创建测试的异步流
- 测试期望的值
- 测试是否完成
- 验证
我们通常使用 create 方法创建基于 Flux 或 Mono 的 StepVerifier,然后就可以进行以下测试:
- 测试期望发出的下一个信号。如果收到其他信号(或者信号与期望不匹配),整个测试就会 失败(AssertionError),如 expectNext(T…)或 expectNextCount(long)。`
- 处理(consume)下一个信号。当你想要跳过部分序列或者当你想对信号内容进行自定义的校验的时候会用到它,可以使用 consumeNextWith(Consumer
)。 - 其他操作,比如暂停或运行一段代码。比如,你想对测试状态或内容进行调整或处理, 你可能会用到 thenAwait(Duration)和 then(Runnable)。
对于终止事件,相应的期望方法(如expectComplete()、expectError(),及其所有的变体方法) 使用之后就不能再继续增加别的期望方法了。最后你只能对 StepVerifier 进行一些额外的配置并 触发校验(通常调用verify()及其变体方法)。
从StepVerifier内部实现来看,它订阅了待测试的 Flux 或 Mono,然后将序列中的每个信号与测试 场景的期望进行比对。如果匹配的话,测试成功。如果有不匹配的情况,则抛出AssertionError异常。
响应式流是一种基于时间的数据流。许多时候,待测试的数据流存在延迟,从而持续一段时间。如果这种场景比较多的话,那么会导致自动化测试运行时间较长。因此StepVerifier提供了可以操作“虚拟时间”的测试方式,这时候需要使用StepVerifier.withVirtualTime来构造。
为了提高 StepVerifier 正常起作用的概率,它一般不接收一个简单的 Flux 作为输入,而是接收 一个 Supplier,从而可以在配置好订阅者之后 “懒创建”待测试的 flux,如:
StepVerifier.withVirtualTime(() -> Mono.delay(Duration.ofDays(1))) //… 继续追加期望方法
有两种处理时间的期望方法,无论是否配置虚拟时间都是可用的:
- thenAwait(Duration)会暂停校验步骤(允许信号延迟发出)。
- expectNoEvent(Duration)同样让序列持续一定的时间,期间如果有任何信号发出则测试失败。
在普通的测试中,两个方法都会基于给定的持续时间暂停线程的执行。而如果是在虚拟时间模式下就相应地使用虚拟时间。
StepVerifier.withVirtualTime(() -> Mono.delay(Duration.ofDays(1))) .expectSubscription() // 1 .expectNoEvent(Duration.ofDays(1)) // 2 .expectNext(0L) .verifyComplete(); // 3
- expectNoEvent 将订阅(subscription)也认作一个事件。假设你用它作为第一步,如果检测 到有订阅信号,也会失败。这时候可以使用 expectSubscription().expectNoEvent(duration) 来代替;
- 期待“一天”内没有信号发生;
- verify 或变体方法最终会返回一个 Duration,这是实际的测试时长。
3.1 map
这里的 map 和 java 8 stream 的 map 是同一个意思,用于元素的转换,像这样
@Test public void reactorMapTest(){ StepVerifier.create(Flux.just(1,2) .map(v->v+1)) .expectNext(2,3) .expectComplete() .verify(); }
还是之前的代码,只是对每一个元素都自增加一,这里就不多说了,对 lambada 熟悉的同学都了解。
3.2 flatmap
flatmap 也是对元素的转换,但是不同的是 flatmap 是将元素转换为流,再将流合并为一个大的流。
@Test public void reactorFlatMapTest(){ StepVerifier.create(Flux.just("crabman","is","hero") .flatMap(v->Flux.fromArray(v.split(""))) .doOnNext(System.out::println)) .expectNextCount(13) .verifyComplete(); }
tips :flatmap 和 map 的区别
从源码上来看 map 就是一个 function 函数,输入一个输出一个,对于 flatmap 来讲它接受的是输出为 Publisher 的 function,也就是说对于 flatmap 来讲 输入一个值,输出的是一个 Publisher,所以 map 是一对一的关系,而 flatmap 是一对多或者多对多的关系,并且两者输出也不一样。那 flatmap 的应用场景在哪里,例如一个接口,入参是 List,用户 id 的集合,需求是返回每个 id 对应的具体信息,所以代码看起来就是这样 xx.flatmap(id->getUserInfoById(id))
3.3 filter
reactor 的 filter 和 java 8 stream 的 filter 是一样的,就不多说了,这里过滤掉值为 2 的
@Test public void reactorFilterTest(){ StepVerifier.create(Flux.just(1,2) .map(v->v+1) .filter(s->s!=2) .doOnNext(System.out::println)) .expectNext(3) .expectComplete() .verify(); }
3.4 zip
这个是操作可能看起来比较陌生,顾名思义,“压缩”就是将多个流一对一的合并起来,还有一个原因,因为在每个 flux 流或者 mono 流里面,各个流的速度是不一样,zip 还有个作用就是将两个流进行同步对齐。例如我们这里在加入另一个流,这个流会不停的发出元素,为了让大家可以感受到同,这里限制另一个流的速度为没 1 秒发出一个元素,这样合并的流也会向另一个流对齐。
@Test public void reactorZipTest(){ //定义一个Flux流 Flux<String> stringFlux = Flux.just("a", "b", "c", "d"); //这里使用计时器,因为在单元测试里面,可能元素没执行完,他就会直接返回 CountDownLatch countDownLatch = new CountDownLatch(1); // 2 Flux.zip(stringFlux,Flux.interval(Duration.ofSeconds(1))) .subscribe(t->System.out.println(t.getT1()) ,System.err::println ,countDownLatch::countDown); try { countDownLatch.await(); } catch (InterruptedException e) { e.printStackTrace(); } }
上面讲的这四个是比较常用的,还有很多。
jdk9 的响应式规范
JDK 9 提供了对于 Reactive 的完整支持,JDK9 也定义了上述提到的四个接口,在java.util.concurrent包上
Flow 的源码
public final class Flow { private Flow() {} // uninstantiable //发布者 @FunctionalInterface public static interface Publisher<T> { public void subscribe(Subscriber<? super T> subscriber); } //订阅者 public static interface Subscriber<T> { public void onNext(T item); public void onError(Throwable throwable); public void onComplete(); } //订阅消费对象 public static interface Subscription { public void request(long n); public void cancel(); } //数据转换 public static interface Processor<T,R> extends Subscriber<T>, Publisher<R> { } static final int DEFAULT_BUFFER_SIZE = 256; public static int defaultBufferSize() { return DEFAULT_BUFFER_SIZE; }}
webFlux
WebFlux 是 Spring 推出响应式编程的一部分(web 端)
响应式编程是异步非阻塞的(是一种基于数据流(data stream)和变化传递(propagation of change)的声明式(declarative)的编程范式)
以往根据不同的应用场景选择不同的技术,有的场景适合用于同步阻塞的,有的场景适合用于异步非阻塞的。而 Spring5 提供了一整套响应式(非阻塞)的技术栈供我们使用(包括 Web 控制器、权限控制、数据访问层等等)。
响应式一般用 Netty 或者 Servlet 3.1 的容器(因为支持异步非阻塞),而 Servlet 技术栈用的是 Servlet 容器

Spring 官方为了让我们更加快速/平滑到 WebFlux 上,之前 SpringMVC 那套都是支持的。也就是说:我们可以像使用 SpringMVC 一样使用着 WebFlux。
WebFlux 使用的响应式流并不是用 JDK9 平台的,而是Reactor响应式流库为啥?因为人家是兄弟公司!
两种路由方式
- 基于 Spring web 的注解声明
- 基于 routing function 的函数式开发
/** * 阻塞5秒钟 * @return */ private String createStr() { try { TimeUnit.SECONDS.sleep(5); } catch (InterruptedException e) { } return "……^ - ^"; } /** * 原mvc * * @return {@link String} */ @GetMapping("/mvc") private String mvc() { long millis = System.currentTimeMillis(); log.info("请求1:{}",millis); String result = createStr(); log.info("结束1:{}",System.currentTimeMillis() - millis); return result; } /** * web flux * * @return {@link Mono<String>} */ @GetMapping("/flux") private Mono<String> flux() { long millis = System.currentTimeMillis(); log.info("请求2:{}",millis); Mono<String> result = Mono.fromSupplier(() -> createStr()); log.info("结束2:{}",System.currentTimeMillis() - millis); return result; }
从调用者(浏览器)的角度而言,是感知不到有什么变化的,因为都是得等待 5s 才返回数据。但是,从服务端的日志我们可以看出,WebFlux 是直接返回 Mono 对象的(而不是像 SpringMVC 一直同步阻塞 5s,线程才返回)。
这正是 WebFlux 的好处:能够以固定的线程来处理高并发(充分发挥机器的性能)。
WebFlux 还支持服务器推送(SSE - >Server Send Event),我们来看个例子:
/** * * 定时 返回0-n个元素 * 注:需要指定MediaType * * @return {@link Flux<String>} */ @GetMapping(value = "/timing", produces = MediaType.TEXT_EVENT_STREAM_VALUE) private Flux<String> timing() { Flux<String> result = Flux .fromStream(IntStream.range(1, 5).mapToObj(i -> { try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { } return "大内密探00" + i; })); return result; }
效果就是每秒会给浏览器推送数据:
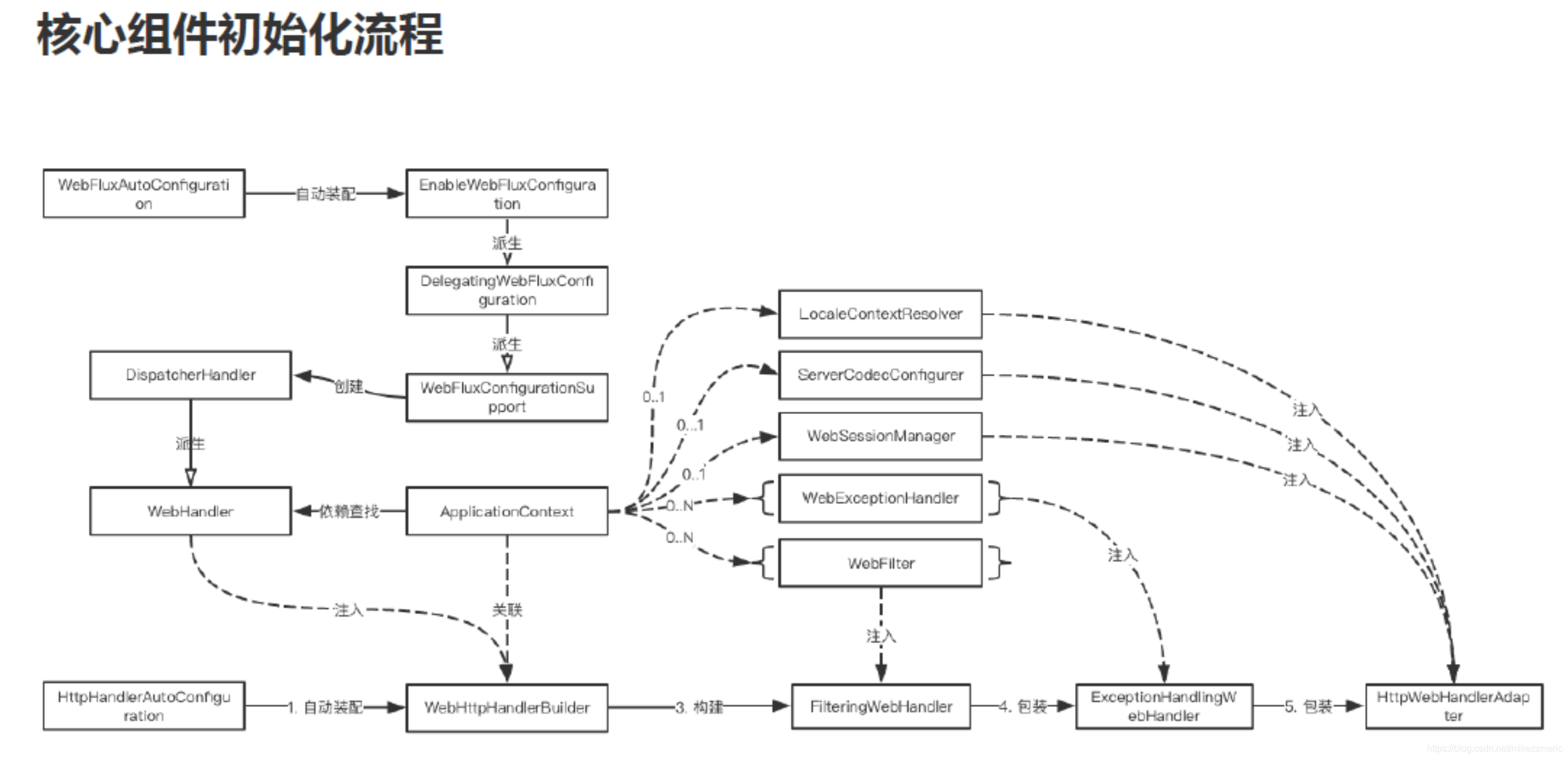
核心组件
1.HttpHandler
是一种带有处理 HTTP 请求和响应方法的简单契约。
2.WebHandler
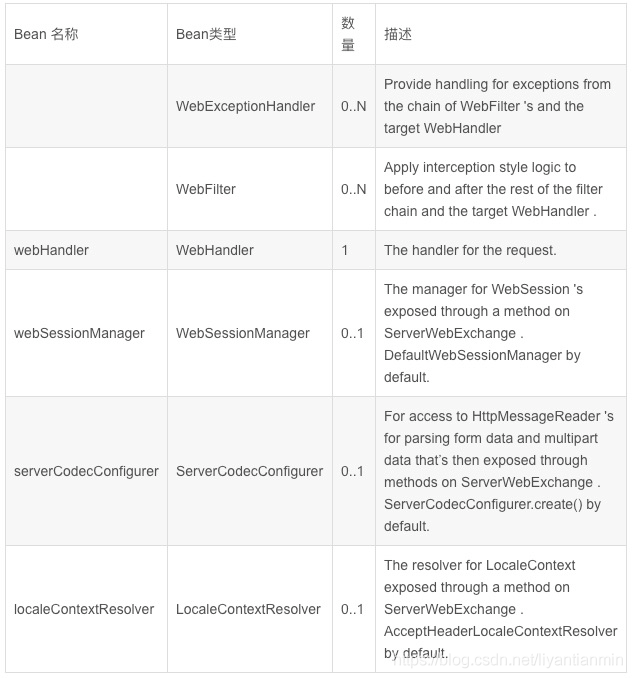
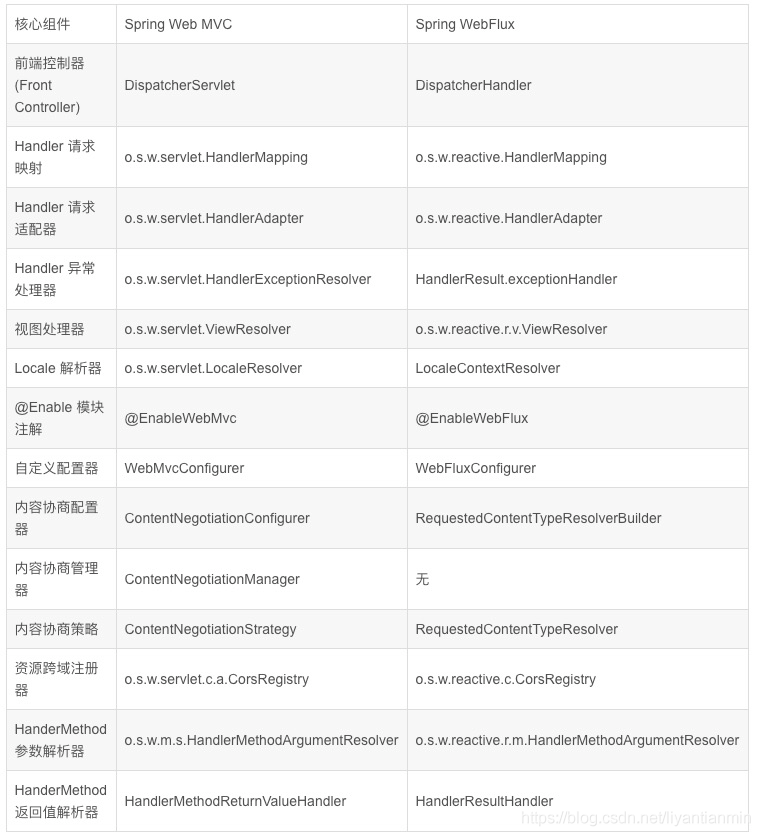
webHandler 显得有一些抽象,我们可以通过对比 SpringMVC 的一些组件帮助大家理解一下在 WebFlux 中各个组件的作用:
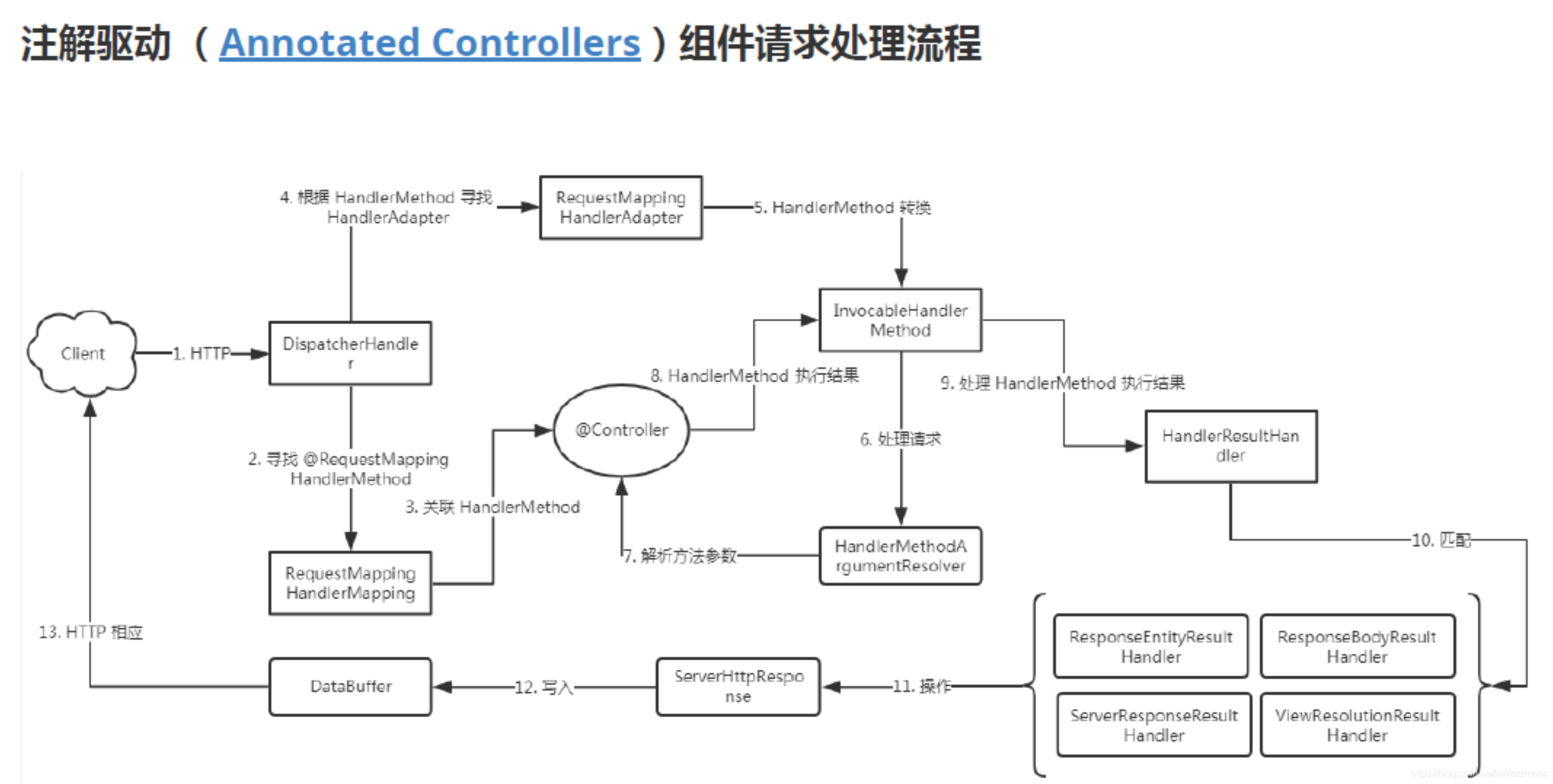
请求处理流程
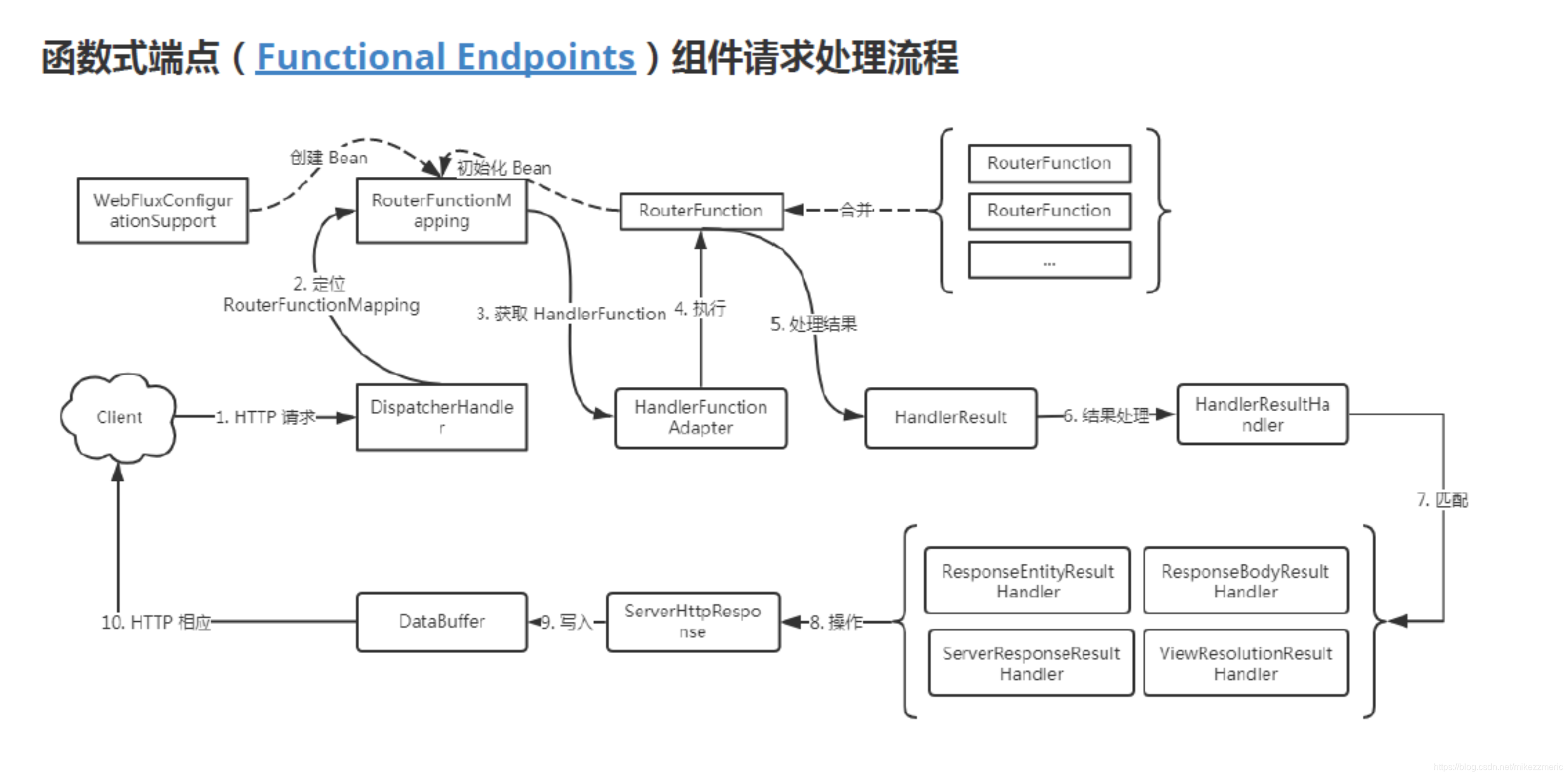
RouterFunctionMapping 中有 private RouterFunction<?> routerFunction;这里面表面看起来只有一个 Bean,其实它里面组合了非常多的 RouterFunction,它是如何根据用户的请求找到对应的 Function 的呢?
// 查询处理器 @Override protected Mono<?> getHandlerInternal(ServerWebExchange exchange) { // 路由函数是否存在 if (this.routerFunction != null) { // 创建请求,并绑定 ServerRequest request = ServerRequest.create(exchange, this.messageReaders); return this.routerFunction.route(request) .doOnNext(handler -> setAttributes(exchange.getAttributes(), request, handler)); } else { // 没有直接空 return Mono.empty(); } }
关键部分就是通过它的成员变量 routerFunction 的 route 方法来找,其实就是通过用户写的 predicate 来判断请求是否相符合,如果符合就返回一个 Mono<HandlerFunction
>
public Mono<HandlerFunction<T>> route(ServerRequest request) { // routerFunction 中的路由谓词匹配 if (this.predicate.test(request)) { if (logger.isTraceEnabled()) { String logPrefix = request.exchange().getLogPrefix(); logger.trace(logPrefix + String.format("Matched %s", this.predicate)); } return Mono.just(this.handlerFunction); } else { return Mono.empty(); } }
总结
反应式编程框架主要采用了观察者模式,而 Spring Reactor 的核心则是对观察者模式的一种衍伸。关于观察者模式的架构中被观察者(Observable)和观察者(Subscriber)处在不同的线程环境中时,由于者各自的工作量不一样,导致它们产生事件和处理事件的速度不一样,这时就出现了两种情况:
- 被观察者产生事件慢一些,观察者处理事件很快。那么观察者就会等着被观察者发送事件好比观察者在等米下锅,程序等待)。
- 被观察者产生事件的速度很快,而观察者处理很慢。那就出问题了,如果不作处理的话,事件会堆积起来,最终挤爆你的内存,导致程序崩溃。(好比被观察者生产的大米没人吃,堆积最后就会烂掉)。为了方便下面理解 Mono 和 Flux,也可以理解为 Publisher(发布者也可以理解为被观察者)主动推送数据给 Subscriber(订阅者也可以叫观察者),如果 Publisher 发布消息太快,超过了 Subscriber 的处理速度,如何处理。这时就出现了 Backpressure(背压—–指在异步场景中,被观察者发送事件速度远快于观察者的处理速度的情况下,一种告诉上游的被观察者降低发送速度的策略)
- WebFlux 提升的其实往往是系统的伸缩性,对于速度的提升没有太多的明显。
- Reactive 编程尽管没有新增大量的代码,然而编码(和调试)却是变得更为复杂
- 现在面临的最大问题是缺少文档。在开发应用中给我们造成了最大障碍。且 Spring WebFlux 尚未证明自身明显地优于 Spring MVC