

springBoot三剑客
springBoot 三板斧
AOP
aop 是一种面向切面编程 能够将那些与业务无关,却为业务模块所共同调用的逻辑或责任(缓存,锁) 封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可拓展性和可维护性
Spring AOP 就是基于动态代理的,如果要代理的对象,实现了某个接口,那么 Spring AOP 会使用 JDK Proxy,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候 Spring AOP 会使用 Cglib ,这时候 Spring AOP 会使用 Cglib 生成一个被代理对象的子类来作为代理,如下图所示:

bean 作用域
- singleton : 唯一 bean 实例,Spring 中的 bean 默认都是单例的。
- prototype : 每次请求都会创建一个新的 bean 实例。
- request : 每一次 HTTP 请求都会产生一个新的 bean,该 bean 仅在当前 HTTP request 内有效。
- session : 每一次 HTTP 请求都会产生一个新的 bean,该 bean 仅在当前 HTTP session 内有效。
- global-session: 全局 session 作用域,仅仅在基于 portlet 的 web 应用中才有意义,Spring5 已经没有了。Portlet 是能够生成语义代码(例如:HTML)片段的小型 Java Web 插件。它们基于 portlet 容器,可以像 servlet 一样处理 HTTP 请求。但是,与 servlet 不同,每个 portlet 都有不同的会话
bean 是否线程安全
的确是存在安全问题的。因为,当多个线程操作同一个对象的时候,对这个对象的成员变量的写操作会存在线程安全问题。
但是,一般情况下,我们常用的 Controller、Service、Dao 这些 Bean 是无状态的。无状态的 Bean 不能保存数据,因此是线程安全的。
常见的有 2 种解决办法:
- 在类中定义一个
ThreadLocal成员变量,将需要的可变成员变量保存在ThreadLocal中(推荐的一种方式)。 - 改变 Bean 的作用域为 “prototype”:每次请求都会创建一个新的 bean 实例,自然不会存在线程安全问题。
生命周期
- Bean 容器找到配置文件中 Spring Bean 的定义。
- Bean 容器利用 Java Reflection API 创建一个 Bean 的实例。
- 如果涉及到一些属性值 利用
set()方法设置一些属性值。 - 如果 Bean 实现了
BeanNameAware接口,调用setBeanName()方法,传入 Bean 的名字。 - 如果 Bean 实现了
BeanClassLoaderAware接口,调用setBeanClassLoader()方法,传入ClassLoader对象的实例。 - 与上面的类似,如果实现了其他
.Aware接口,就调用相应的方法。 - 如果有和加载这个 Bean 的 Spring 容器相关的
BeanPostProcessor对象,执行postProcessBeforeInitialization()方法 - 如果 Bean 实现了
InitializingBean接口,执行afterPropertiesSet()方法。 - 如果 Bean 在配置文件中的定义包含 init-method 属性,执行指定的方法。
- 如果有和加载这个 Bean 的 Spring 容器相关的
BeanPostProcessor对象,执行postProcessAfterInitialization()方法 - 当要销毁 Bean 的时候,如果 Bean 实现了
DisposableBean接口,执行destroy()方法。 - 当要销毁 Bean 的时候,如果 Bean 在配置文件中的定义包含 destroy-method 属性,执行指定的方法。
MVC
流程说明(重要):
- 客户端(浏览器)发送请求,直接请求到
DispatcherServlet。 DispatcherServlet根据请求信息调用HandlerMapping,解析请求对应的Handler。- 解析到对应的
Handler(也就是我们平常说的Controller控制器)后,开始由HandlerAdapter适配器处理。 HandlerAdapter会根据Handler来调用真正的处理器来处理请求,并处理相应的业务逻辑。- 处理器处理完业务后,会返回一个
ModelAndView对象,Model是返回的数据对象,View是个逻辑上的View。 ViewResolver会根据逻辑View查找实际的View。DispaterServlet把返回的Model传给View(视图渲染)。- 把
View返回给请求者(浏览器)
有哪些设计模式
- 工厂设计模式 : Spring 使用工厂模式通过
BeanFactory、ApplicationContext创建 bean 对象。 - 代理设计模式 : Spring AOP 功能的实现。
- 单例设计模式 : Spring 中的 Bean 默认都是单例的。
- 模板方法模式 : Spring 中
jdbcTemplate、hibernateTemplate等以 Template 结尾的对数据库操作的类,它们就使用到了模板模式。 - 包装器设计模式 : 我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
- 观察者模式: Spring 事件驱动模型就是观察者模式很经典的一个应用。
- 适配器模式 :Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器模式适配
Controller。
事务
事务方式
- 编程式事务,在代码中硬编码。(不推荐使用)
- 声明式事务,在配置文件中配置(推荐使用)
声明式事务又分为两种:
- 基于 XML 的声明式事务
- 基于注解的声明式事务
隔离级别
ransactionDefinition 接口中定义了五个表示隔离级别的常量:
- TransactionDefinition.ISOLATION_DEFAULT: 使用后端数据库默认的隔离级别,Mysql 默认采用的 REPEATABLE_READ 隔离级别 Oracle 默认采用的 READ_COMMITTED 隔离级别.
- TransactionDefinition.ISOLATION_READ_UNCOMMITTED: 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读
- TransactionDefinition.ISOLATION_READ_COMMITTED: 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生
- TransactionDefinition.ISOLATION_REPEATABLE_READ: 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
- TransactionDefinition.ISOLATION_SERIALIZABLE: 最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
传播行为
支持当前事务的情况:
- TransactionDefinition.PROPAGATION_REQUIRED: 如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
- TransactionDefinition.PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
- TransactionDefinition.PROPAGATION_MANDATORY: 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)
不支持当前事务的情况:
- TransactionDefinition.PROPAGATION_REQUIRES_NEW: 创建一个新的事务,如果当前存在事务,则把当前事务挂起。
- TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。
- TransactionDefinition.PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。
其他情况:
- TransactionDefinition.PROPAGATION_NESTED: 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于 TransactionDefinition.PROPAGATION_REQUIRED。
IOC
IOC 是一种设计思想,它有一个容器用来存放对象引用。IoC 容器是 Spring 用来实现 IoC 的载体 将原本在程序中手动创建对象的控制权,交由 Spring 框架来管理 IoC 容器实际上就是个 Map(key,value),Map 中存放的是各种对象。
Spring IoC 的初始化过程:

spring 怎么解决循环依赖
Spring 整个解决循环依赖问题的实现思路已经比较清楚了。对于整体过程,读者朋友只要理解两点:
- Spring 是通过递归的方式获取目标 bean 及其所依赖的 bean 的;
- Spring 实例化一个 bean 的时候,是分两步进行的,首先实例化目标 bean,然后为其注入属性。
结合这两点,也就是说,Spring 在实例化一个 bean 的时候,是首先递归的实例化其所依赖的所有 bean,直到某个 bean 没有依赖其他 bean,此时就会将该实例返回,然后反递归的将获取到的 bean 设置为各个上层 bean 的属性的。
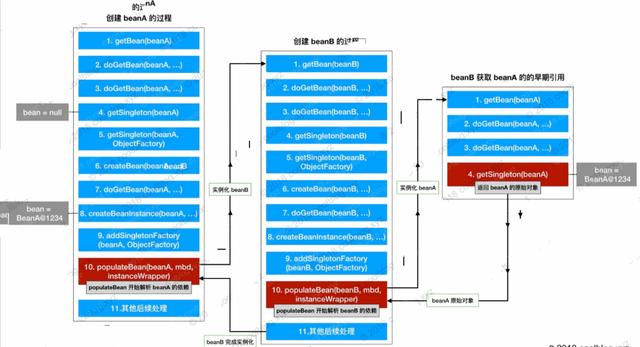
三级缓存
如何解决循环依赖,Spring 主要的思路就是依据三级缓存,在实例化 A 时调用 doGetBean,发现 A 依赖的 B 的实例,此时调用 doGetBean 去实例 B,实例化的 B 的时候发现又依赖 A,如果不解决这个循环依赖的话此时的 doGetBean 将会无限循环下去,导致内存溢出,程序奔溃。spring 引用了一个早期对象,并且把这个”早期引用”并将其注入到容器中,让 B 先完成实例化,此时 A 就获取 B 的引用,完成实例化。
Spring 能够轻松的解决属性的循环依赖正式用到了三级缓存,在 AbstractBeanFactory 中有详细的注释。

一级缓存:singletonObjects,存放完全实例化属性赋值完成的 Bean,直接可以使用。二级缓存:earlySingletonObjects,存放早期 Bean 的引用,尚未属性装配的 Bean 三级缓存:singletonFactories,三级缓存,存放实例化完成的 Bean 工厂。
根据以上的分析,大概清楚了 Spring 是如何解决循环依赖的。假设 A 依赖 B,B 依赖 A(注意:这里是 set 属性依赖)分以下步骤执行:A 依次执行doGetBean、查询缓存、createBean创建实例,实例化完成放入三级缓存 singletonFactories 中,接着执行populateBean方法装配属性,但是发现有一个属性是 B 的对象。因此再次调用 doGetBean 方法创建 B 的实例,依次执行 doGetBean、查询缓存、createBean 创建实例,实例化完成之后放入三级缓存 singletonFactories 中,执行 populateBean 装配属性,但是此时发现有一个属性是 A 对象。因此再次调用 doGetBean 创建 A 的实例,但是执行到 getSingleton 查询缓存的时候,从三级缓存中查询到了 A 的实例(早期引用,未完成属性装配),此时直接返回 A,不用执行后续的流程创建 A 了,那么 B 就完成了属性装配,此时是一个完整的对象放入到一级缓存 singletonObjects 中。B 创建完成了,则 A 自然完成了属性装配,也创建完成放入了一级缓存 singletonObjects 中。Spring 三级缓存的应用完美的解决了循环依赖的问题,下面是循环依赖的解决流程图。
SPI(自动装配)
1)SPI 思想
- SPI 的全名为 Service Provider Interface.这个是针对厂商或者插件的。
- SPI 的思想:系统里抽象的各个模块,往往有很多不同的实现方案,比如日志模块的方案,xml 解析模块、jdbc 模块的方案等。面向的对象的设计里,我们一般推荐模块之间基于接口编程,模块之间不对实现类进行硬编码。一旦代码里涉及具体的实现类,就违反了可拔插的原则,如果需要替换一种实现,就需要修改代码。为了实现在模块装配的时候能不在程序里动态指明,这就需要一种服务发现机制。java spi 就是提供这样的一个机制:为某个接口寻找服务实现的机制
(2)SPI 约定
- 当服务的提供者,提供了服务接口的一种实现之后,在 jar 包的 META-INF/services/目录里同时创建一个以服务接口命名的文件。该文件里就是实现该服务接口的具体实现类。而当外部程序装配这个模块的时候,就能通过该 jar 包 META-INF/services/里的配置文件找到具体的实现类名,并装载实例化,完成模块的注入。通过这个约定,就不需要把服务放在代码中了,通过模块被装配的时候就可以发现服务类了。
springboot 最重要的特性就是自动配置,许多功能不需要手动开启,会自动帮助程序员开启,如果想扩展某些
第三方组件的功能,例如mybatis,只需要配置依赖,就可以了,这其中都是需要SPI支持实现的,下面我们从源码
层面看看springboot如何通过spi机制实现自动配置的。
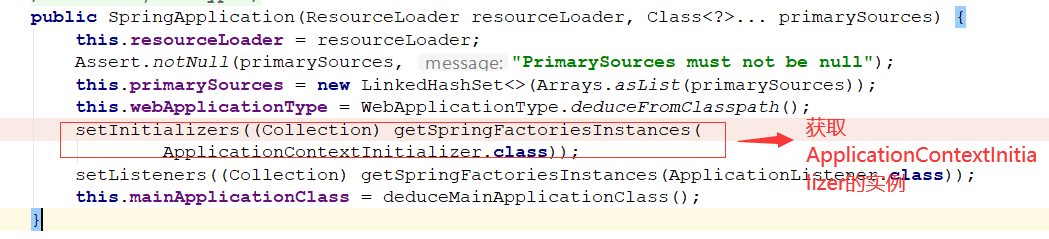
spring.factories
加载所有工程中META-INF/spring.factories文件中的配置
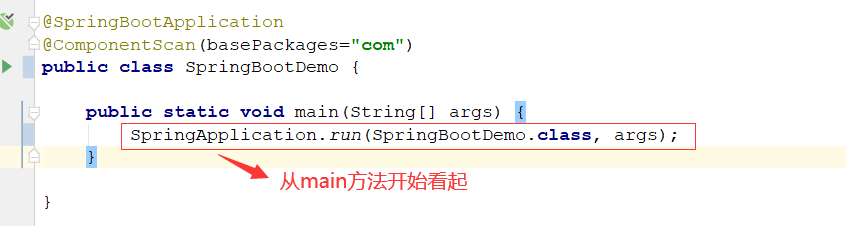
创建 SpringApplication 对象:

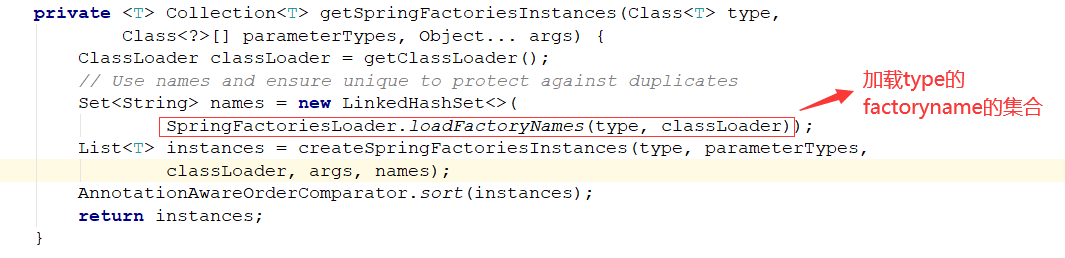

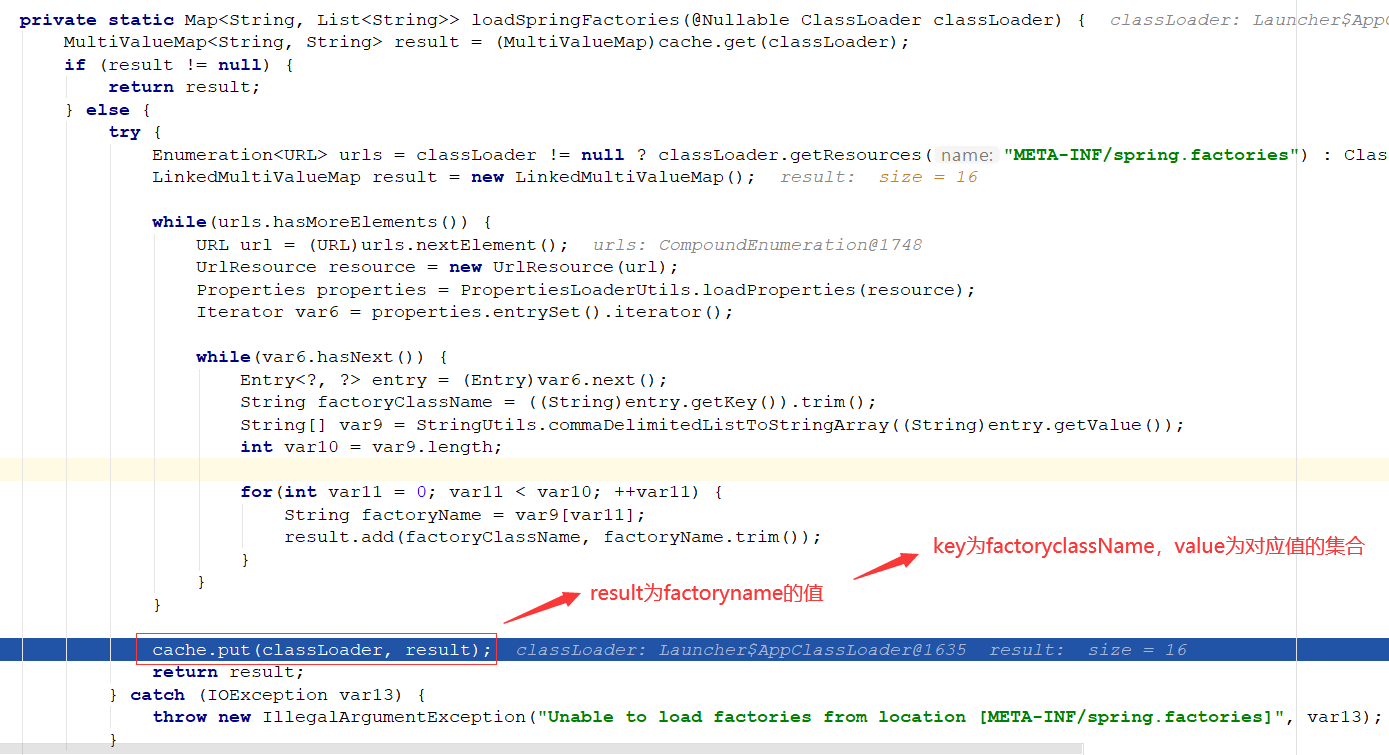
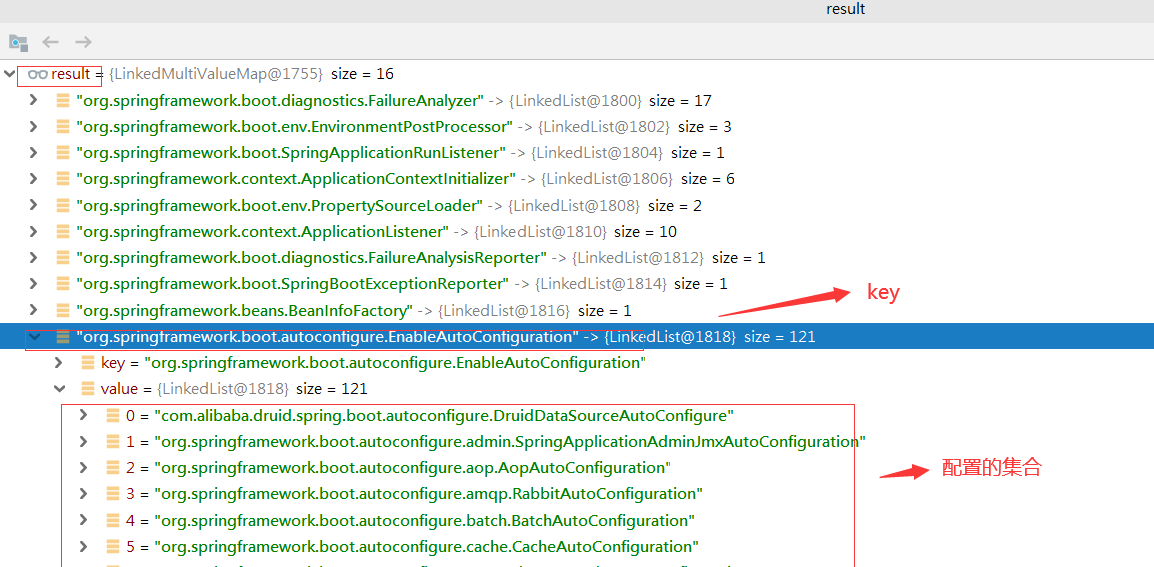
我们随便看一个工程的目录:spring-boot-autoconfigure 工程下 META-INF 目录下的 spring.factories 文件的内容, 配置类似 map ,key 为某一项,value 为实现集合

这就是 Spi 的加载机制,可以通过配置的方式实现和业务代码的解耦,需要增加时直接配置到文件内。
这一步是在容器启动的时候,加载所有的 factoryname 的值到缓存,包括自动配置的。
如何寻找并注册
看一下这个注解@SpringBootApplication
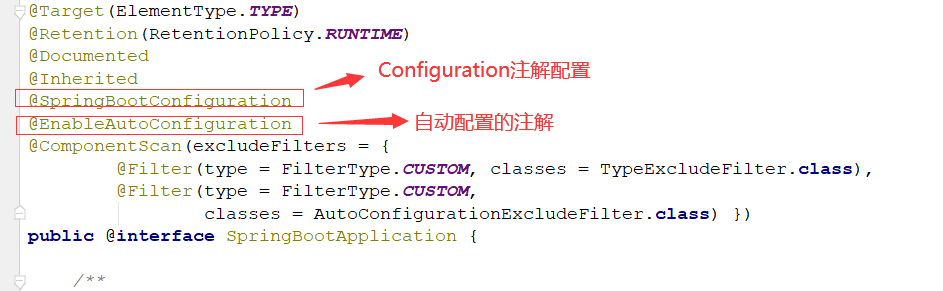
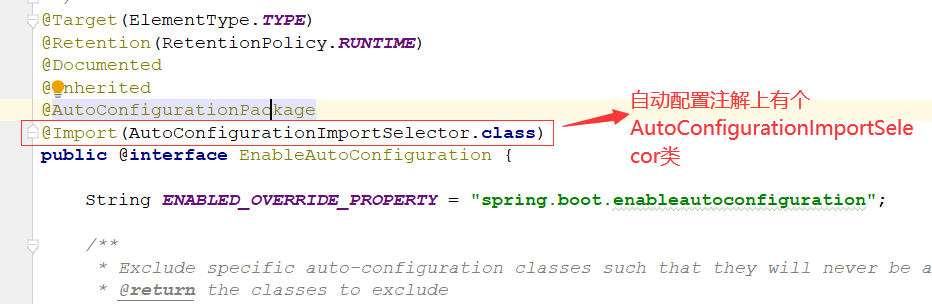
看一下这个类的内容:类里面有获取自动配置的方法 getAutoConfigrationEntry
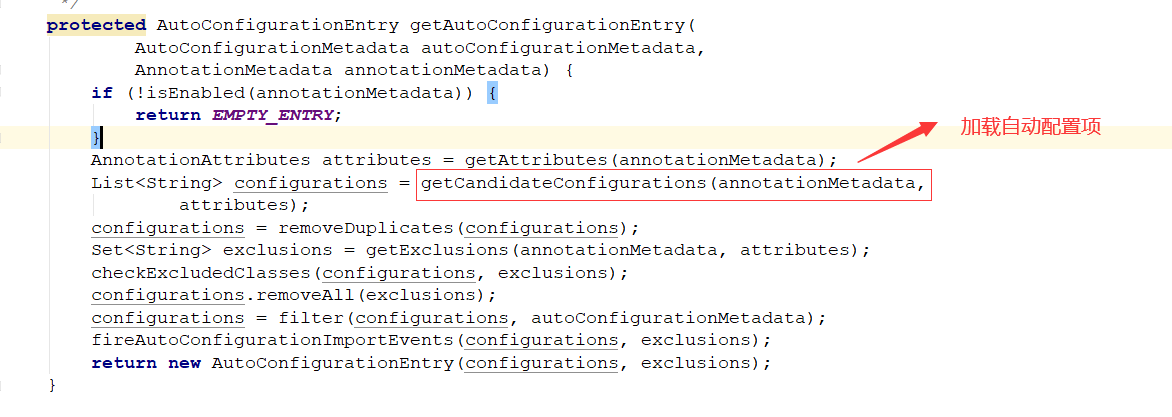
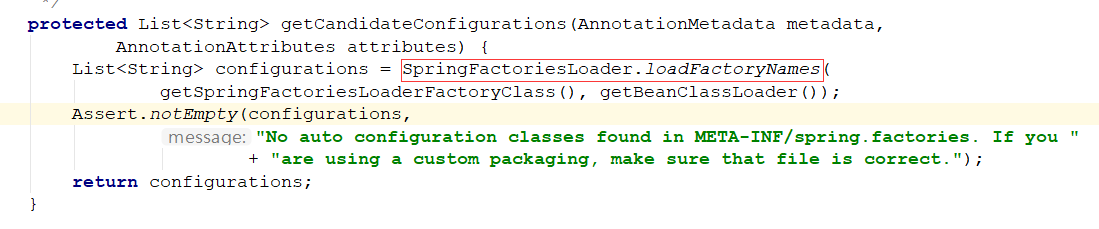

就是从上一步缓存 result 中查询所有的 EnableAutoConfiguration 的 value 集合,
这一节主要分析 spi 机制加载 spring.factories 的配置项,下一节我们来分析自动配置的加载流程
|